We recently got a new Vicon motion capture system installed in our robot arena here at Essex. It's an amazing piece of equipment. Able to track hundreds of infrared reflectors at a 100 hz or more with millimetre precision, you can even use it to track the spinning blades of a micro-helicopter!
The video below is from our first experiments with tracking a real radio-controlled toy car with the Vicon system, and controlling it from a desktop computer via a hacked transmitter connected to the parallel port (as in earlier experiments using webcams).
Although the car above was controlled by a hard-coded algorithm (about 15 lines of code!) we think we can do significantly better through a learned, and possibly learning, controller. So right now we are working on an approach to automatically inferring models of the car dynamics, evolving controllers for these models, and using the controllers thus learned in simulation to control the real car. We (as usual I'm working with Simon, but right now also with Renzo, Richard and Hugo) have a couple of exciting ideas about this, which I might blog about as soon as we've convinced ourselves that they actually work. Stay tuned!
Tuesday, December 05, 2006
Wednesday, October 25, 2006
Simulated car racing competition
I am running the simulated car racing competition for CIG 2007. The problem is a bit different from the versions of the car racing problem we've been exploring so far in that there are no walls, and the next two waypoints are visible to the controller. But there are similarities as well - in fact, quite a bit of the simulation code is reused from my earlier experiments...
Please consider taking part in the competition - the final rules are not online yet (will be really soon, promise), but the code is there for you to start playing around with. It will be really interesting to see what sort of controller the winner will be - hand-coded? Evolved neural network? Fuzzy logic? Genetic programming? Learned through temporal difference learning? Something completely different? (Probably it will be some sort of hybrid of man and machine efforts. Hybrids always win in the end.)
So, off you go. Have a look at the competition, and start designing your controllers.
Yes, I mean you.
Please consider taking part in the competition - the final rules are not online yet (will be really soon, promise), but the code is there for you to start playing around with. It will be really interesting to see what sort of controller the winner will be - hand-coded? Evolved neural network? Fuzzy logic? Genetic programming? Learned through temporal difference learning? Something completely different? (Probably it will be some sort of hybrid of man and machine efforts. Hybrids always win in the end.)
So, off you go. Have a look at the competition, and start designing your controllers.
Yes, I mean you.
Monday, October 09, 2006
That's more like me
Richard needed a face to use on a cube for his humanoid robot to play with (don't ask) so he put me up against the wall and took a shot. I think it captures the inside of me pretty well, maybe better than it captures the outside of me.


Friday, October 06, 2006
SAB 2006 Workshop on Adaptive Approaches for Optimizing...
...Player Satisfaction in Computer and Physical Games is the rather long title of a workshop I visited in Rome last week. It was organized by Georgios Yannakakis and John Hallam, who wish this to be the first of a series of workshops dealing with how various computational intelligence techniques can be used to make games more entertaining - a most laudable initiative, and a good start to the series. The workshop featured seven academic papers and one invited talk from Hakon Steinö, and of course lots of good discussion over pizza and white russian.
Our paper there had a long title too: Making racing fun through player modeling and track evolution. I must say that I think this is a quite good paper, definitely one of the better I've (co-)written. It deals with how to identify and reproduce a human player's driving behaviour in a racing game, and use thus behavioural model to automatically create tracks that are "fun" for the player.
Of course, how to measure "fun" in a game is a question which is far from settled. But an interesting question, and potentially industrially relevant. The issue of automatically creating content (e.g. racing tracks) for games seems to be quite hot as well - fertile ground for research indeed.
Our paper there had a long title too: Making racing fun through player modeling and track evolution. I must say that I think this is a quite good paper, definitely one of the better I've (co-)written. It deals with how to identify and reproduce a human player's driving behaviour in a racing game, and use thus behavioural model to automatically create tracks that are "fun" for the player.
Of course, how to measure "fun" in a game is a question which is far from settled. But an interesting question, and potentially industrially relevant. The issue of automatically creating content (e.g. racing tracks) for games seems to be quite hot as well - fertile ground for research indeed.
Wednesday, September 13, 2006
PPSN 2006 Conference report
So, the conference is over now, and I look forward to a few days of doing nothing at all. (Well, maybe visit a museum or two, or go hiking on a glacier, but I mean nothing involving evolutionary computation.) The last afternoon was spent in the Blue Lagoon, an outdoor thermal bath, making this one of the precious few scientific conferences where you get to see the other participants in only swimwear. A shame, though, that the population in question has so little "diversity".
So, how was the conference itself? Good. Very well organized, and fabulous for networking, because of the small size, poster-only presentations, and generally good atmosphere. It really made you feel part of the community, much more so than for example CEC does. So much part of the community that I'm really reluctant to write anything negative about the conference. (Maybe I should get an anonymous blog as well?)
The one thing I could complain about was that the conference was rather focused on theory and basic empirical research, and I might be a bit more of an applications guy. That's more of a problem with me than with the conference, however. And there were plenty of papers I did enjoy. I tend to enjoy theory when I understand it. My good friend Alberto won the best student paper award, which I think was well-deserved. His theory is one of those I do understand.
We also had some very good keynotes, especially the one from Edward Tsang on computational finance. And it was possibly to pick up some of the trends in the community. Basically everybody seems to be involved in Multiobjective Optimization, which I find potentially useful, and quite a few people are doing Evolution Strategies with Covariance Matrix Adaptation, which I find completely incomprehensible.
But I must say that quite a few people took an interest in my own paper as well, in spite of it being so different from most other papers there. Or maybe because of that.
So, how was the conference itself? Good. Very well organized, and fabulous for networking, because of the small size, poster-only presentations, and generally good atmosphere. It really made you feel part of the community, much more so than for example CEC does. So much part of the community that I'm really reluctant to write anything negative about the conference. (Maybe I should get an anonymous blog as well?)
The one thing I could complain about was that the conference was rather focused on theory and basic empirical research, and I might be a bit more of an applications guy. That's more of a problem with me than with the conference, however. And there were plenty of papers I did enjoy. I tend to enjoy theory when I understand it. My good friend Alberto won the best student paper award, which I think was well-deserved. His theory is one of those I do understand.
We also had some very good keynotes, especially the one from Edward Tsang on computational finance. And it was possibly to pick up some of the trends in the community. Basically everybody seems to be involved in Multiobjective Optimization, which I find potentially useful, and quite a few people are doing Evolution Strategies with Covariance Matrix Adaptation, which I find completely incomprehensible.
But I must say that quite a few people took an interest in my own paper as well, in spite of it being so different from most other papers there. Or maybe because of that.
Tuesday, September 12, 2006
New papers online
Two new papers on the evolutionary car racing project are now available on my home page. One will be presented on a small workshop in Rome in a few weeks time, the other was presented at PPSN yesterday. Yes, that means I am in Iceland right now. What it's like over here? Cold and expensive. But not without its charm. I'll be back soon with a conference report of some sort.
Tuesday, August 01, 2006
Learning to fly
The Gridswarms project, on which my friend Renzo is working, is about creating swarms of miniature helicopters that fly around and share their computing resources in order to perform tasks in a coordinated manner, inspired by the way they do it on the Discovery Channel. (That is, inspired by cooperation among insects. Nothing else.)
Yes, it sounds pretty science fiction, and yes, it's been covered several times by the media, e.g. Wired. And I'm pretty sure they will succeed as well.
I'm not officially part of that project, but as I tend to hang out with Renzo all the time, we cooperate quite a bit on our research as well. Only on things we both understand, of course; I hardly know anything about hardware design, Kalman filters and such stuff. One problem I could help him with, though, is the automatic design of the basic helicopter controller.
You see, the plan is to have the helicopters perform all sorts of interesting flocking and swarming behaviour, perhaps coordinated target tracking, or distributed surveillance. But these advanced behaviours need to be built on top of a reliable flight controller layer, whose task it is to keep the machine flying in the face of various disturbances, and implement the orders (e.g. "go to point x, y, z, but quickly!") of the swarming layers.
Designing such a controller by hand is in no way easy. It is even harder than actually flying the helicopter, which I can tell you is not easy at all. So we turned to evolutionary algorithms and neural networks to do the job for us.
Now, what an evolutionary algorithm does is essentially systematical trial-and-error on a massive scale. Doing massive trial and error on real helicopters (albeit miniature) would be a bit... expensive. Not to mention slow. So we needed to do the evolution in simulation, and because the real helicopters are still under developments we had to contend with a third-party (very detailed) helicopter simulation for the time being.
Without further ado, this is what it looks like. Remember that we have provided absolutely no knowledge of how to fly the helicopter to the neural network, it has learnt it all by itself, through evolution!
As you might or might not see from the movie, the task is to fly a trajectory defined by a number of waypoints (yellow). (As should be evident from the movie, the helicopter is shown from behind in the right panel and from above in the left panel.) Our evolved neural networks perform this task much better than a hand-coded PID controller, and is reliable even under various disturbances, such as changing wind conditions. And as far as we know, we are the first people in the world to successfully evolve helicopter control.
Getting there wasn't all that easy, though. To begin with, the computational complexity is absolutely massive - we used a cluster of 34 Linux computers, and even then a typical evolutionary run (a hundred generations or so) took several hours. What we also discovered was that no matter how much computer power you have, the right behaviour won't evolve if the structure of the neural network is wrong. It took us a lot of time to find out, but a standard fully connected MLP net won't cut it. Instead you have modularize either according to the dimensions of control or according to...
...but hey, I'm losing you. I can't get too far into technical details on a blog, can I? Go read the paper we presented at CEC two weeks ago instead. It is available online, click here!
Anyway, there is more work to do on the project, and I'll get back to this topic!
Yes, it sounds pretty science fiction, and yes, it's been covered several times by the media, e.g. Wired. And I'm pretty sure they will succeed as well.
I'm not officially part of that project, but as I tend to hang out with Renzo all the time, we cooperate quite a bit on our research as well. Only on things we both understand, of course; I hardly know anything about hardware design, Kalman filters and such stuff. One problem I could help him with, though, is the automatic design of the basic helicopter controller.
You see, the plan is to have the helicopters perform all sorts of interesting flocking and swarming behaviour, perhaps coordinated target tracking, or distributed surveillance. But these advanced behaviours need to be built on top of a reliable flight controller layer, whose task it is to keep the machine flying in the face of various disturbances, and implement the orders (e.g. "go to point x, y, z, but quickly!") of the swarming layers.
Designing such a controller by hand is in no way easy. It is even harder than actually flying the helicopter, which I can tell you is not easy at all. So we turned to evolutionary algorithms and neural networks to do the job for us.
Now, what an evolutionary algorithm does is essentially systematical trial-and-error on a massive scale. Doing massive trial and error on real helicopters (albeit miniature) would be a bit... expensive. Not to mention slow. So we needed to do the evolution in simulation, and because the real helicopters are still under developments we had to contend with a third-party (very detailed) helicopter simulation for the time being.
Without further ado, this is what it looks like. Remember that we have provided absolutely no knowledge of how to fly the helicopter to the neural network, it has learnt it all by itself, through evolution!
As you might or might not see from the movie, the task is to fly a trajectory defined by a number of waypoints (yellow). (As should be evident from the movie, the helicopter is shown from behind in the right panel and from above in the left panel.) Our evolved neural networks perform this task much better than a hand-coded PID controller, and is reliable even under various disturbances, such as changing wind conditions. And as far as we know, we are the first people in the world to successfully evolve helicopter control.
Getting there wasn't all that easy, though. To begin with, the computational complexity is absolutely massive - we used a cluster of 34 Linux computers, and even then a typical evolutionary run (a hundred generations or so) took several hours. What we also discovered was that no matter how much computer power you have, the right behaviour won't evolve if the structure of the neural network is wrong. It took us a lot of time to find out, but a standard fully connected MLP net won't cut it. Instead you have modularize either according to the dimensions of control or according to...
...but hey, I'm losing you. I can't get too far into technical details on a blog, can I? Go read the paper we presented at CEC two weeks ago instead. It is available online, click here!
Anyway, there is more work to do on the project, and I'll get back to this topic!
Sunday, July 30, 2006
WCCI 2006 conference report
As of yesterday, I'm back from Canada. Vancouver is fantastic, and I certainly wouldn't mind moving there. The conference (WCCI/CEC) was not bad either, though a bit too big - how are you supposed to find the information you are interested in among a total of almost 1600 papers, including 400-500 on evolutionary stuff?
There was some excellent stuff presented, including the keynotes by Sebastian Thrun and Risto Miikkulainen, and some individual papers, such as a simple but ingenious co-evolutionary algorithm by Thomas Miconi.
As usual, there was also a lot of "noise" - it is astonishing how many papers are presented that, while not being technically incorrect, makes insignificant progress on insignificant topics, and just makes you wonder why. Why did anyone care to write these papers, and then travel far away to present them to not very interested audiences? Because the authors didn't have any better research ideas, and desperately needed to lengthen their publication lists in order to get their PhDs / obtain funding / get tenure etc.? Probably.
As Philip Ball notes in his book Critical Mass, more than half of all scientific papers don't get cited at all, except by their authors. Makes you think. (And no, I haven't had that many citations either - yet...)
Anyway, back to the conference. It all started out with a quite amusing keynote by Robert Hecht-Nielsen, who presented an "Architecture of cognition",speaking preaching with no shortage of confidence and enthusiasm. What he actually presented was an example application based on a form of Hebbian learning, which could generate complete sentences based on afew trigger words and large amounts of previously scanned text. From a linguistic standpoint his invention indeed seems rather radical, as it produces correct English grammar without any explicit rules of grammar at all. But the suggestion that it has any kind of "real" intelligence is quite stupid, as the sentences produced were most often simply not true, and there is no mechanism by which it can learn from mistakes or suppress false information. Intelligence requires some sort of interaction with the environment, and I'm more prepared to say that a thermostat is intelligent than that Hecht-Nielsens program is. As someone on the conference said, what he presented was a bullshit engine. A good one apparently, and potentially useful, but still only a bullshit engine. A little bit like Eliza.
My own talk received fairly good feedback, and I had some stimulating discussions, including some industry people. I'm looking forward to PPSN, though, where the format of the presentations is more focused on interaction.
There was some excellent stuff presented, including the keynotes by Sebastian Thrun and Risto Miikkulainen, and some individual papers, such as a simple but ingenious co-evolutionary algorithm by Thomas Miconi.
As usual, there was also a lot of "noise" - it is astonishing how many papers are presented that, while not being technically incorrect, makes insignificant progress on insignificant topics, and just makes you wonder why. Why did anyone care to write these papers, and then travel far away to present them to not very interested audiences? Because the authors didn't have any better research ideas, and desperately needed to lengthen their publication lists in order to get their PhDs / obtain funding / get tenure etc.? Probably.
As Philip Ball notes in his book Critical Mass, more than half of all scientific papers don't get cited at all, except by their authors. Makes you think. (And no, I haven't had that many citations either - yet...)
Anyway, back to the conference. It all started out with a quite amusing keynote by Robert Hecht-Nielsen, who presented an "Architecture of cognition",
My own talk received fairly good feedback, and I had some stimulating discussions, including some industry people. I'm looking forward to PPSN, though, where the format of the presentations is more focused on interaction.
Wednesday, July 12, 2006
Another evolutionary car racing video
Here is an evolved car controller navigating a rather difficult track. I usually do worse than the controller does when I try to drive that track myself, frequently colliding with walls and having to back up and try again. Note that it seems impossible to evolve a controller for this track from scratch, instead I had to start from a controller that was previously evolved to drive several easier tracks. Evolution had to progress in an incremental fashion.
For more on this, read my previous post on evolutionary car racing.
For more on this, read my previous post on evolutionary car racing.
Tuesday, July 11, 2006
Reinforcement learning - what is it, really? And why won't it work?
At the moment I'm working on several car racing-related projects simultaneously, but the one that's receiving the most attention is trying to compare evolution with reinforcement learning, to see if I can achieve the same results with those methods.
Well, I suppose I should say that I try to compare evolution with other forms of reinforcement learning. After all, evolutionary algorithms are just one set of ways of solving reinforcement learning problems.
It turns out not to be very easy at all to get anything working. I've tried learning values of state-action pairs from a good driver; this might not really be reinforcement learning but rather some sort of supervised learning, and anyway it doesn't work. I'm now working on simultaneous learning of forward models and sensor-state value estimators, which frankly seems unnecessarily complicated.
Of course, it must be possible to apply reinforcement learning to car driving, and I'm sure people have done it. But I am pretty sure it has not been done with the limited information I'm giving the controller. Anything is easy when you cheat, and part of my research program is not to cheat.
Anyway, I'm off to CEC in a few days. I'm bringing the Sutton and Barto book to read on the flight, hopefully I'll get an insight or two.
Well, I suppose I should say that I try to compare evolution with other forms of reinforcement learning. After all, evolutionary algorithms are just one set of ways of solving reinforcement learning problems.
It turns out not to be very easy at all to get anything working. I've tried learning values of state-action pairs from a good driver; this might not really be reinforcement learning but rather some sort of supervised learning, and anyway it doesn't work. I'm now working on simultaneous learning of forward models and sensor-state value estimators, which frankly seems unnecessarily complicated.
Of course, it must be possible to apply reinforcement learning to car driving, and I'm sure people have done it. But I am pretty sure it has not been done with the limited information I'm giving the controller. Anything is easy when you cheat, and part of my research program is not to cheat.
Anyway, I'm off to CEC in a few days. I'm bringing the Sutton and Barto book to read on the flight, hopefully I'll get an insight or two.
Tuesday, June 27, 2006
Sticky stuff
Those stickers had been disgracing mine and Renzo's already ugly computers for much too long. Finally we decided to put them where they belong.


Hmm... what more can you do with these stickers?


Hmm... what more can you do with these stickers?
Why do I keep reading Digg when Slashdot is better?
They say Digg is bigger than Slashdot than these days. Bigger, better, newer, 2.0 and what not.
Indeed, I find myself scanning the Digg front page more often than Slashdot's ditto. Far too often, actually. Obsessively often? Well well, I actually get proper work done now and then.
Still, it's simply not true that the quality of the "news" on Digg's frontpage is higher than the news on Slashdot. On the contrary, Digg suffers from a disgusting amount of mob mentality. Half of what's on the front page is not news at all, merely short text snippets propagating rumours that everybody's already heard or views that most people already agree with. Which is why they get digged to the front page: people like to hear/read what they already believe in.
And this is not really a problem with Digg, it's a problem with people. (And like all problems we can't really do anything about, it's not even worth thinking of it as a problem, just as a fact.)
Slashdot, on the other hand, has sometimes-competent editors that sometimes put an effort into selecting and editing stories. While I might learn something I didn't already know from either Digg or Slashdot, I'm far more likely to learn something new about something I didn't already know anything about from Slashdot. Crucial difference.
So, back to the question: Why do I keep reading Digg when Slashdot is better? Because the Digg is updated more often, and the items are shorter. It's that simple. I think.
Indeed, I find myself scanning the Digg front page more often than Slashdot's ditto. Far too often, actually. Obsessively often? Well well, I actually get proper work done now and then.
Still, it's simply not true that the quality of the "news" on Digg's frontpage is higher than the news on Slashdot. On the contrary, Digg suffers from a disgusting amount of mob mentality. Half of what's on the front page is not news at all, merely short text snippets propagating rumours that everybody's already heard or views that most people already agree with. Which is why they get digged to the front page: people like to hear/read what they already believe in.
And this is not really a problem with Digg, it's a problem with people. (And like all problems we can't really do anything about, it's not even worth thinking of it as a problem, just as a fact.)
Slashdot, on the other hand, has sometimes-competent editors that sometimes put an effort into selecting and editing stories. While I might learn something I didn't already know from either Digg or Slashdot, I'm far more likely to learn something new about something I didn't already know anything about from Slashdot. Crucial difference.
So, back to the question: Why do I keep reading Digg when Slashdot is better? Because the Digg is updated more often, and the items are shorter. It's that simple. I think.
Tuesday, June 20, 2006
List of researchers/centres active in Computational Intelligence and Games
I thought a list of researchers and research centres working in the field of Computational Intelligence and Games (CIG) would be a useful resource to people like myself. For a definition of CIG, see the eponymous conference series; in short, it's about applying techniques such as evolutionary computation, reinforcement learning and neural networks to computer games, like strategy games, shooters, platformers, driving games and board games.
The format of the list would be the institution (university, company etc.), followed by a list of relevant researchers (those who spend a significant amount of their time on CIG research), and possibly a few words about what the topics of research are. The list is meant to be continuously updated: I am fully aware it is far from complete at the moment, so please help me expand it by posting additions and corrections to the list in the comments below! This post will then be updated as additions come in.
Brandeis University: Jordan Pollack. Co-evolution, theory, backgammon.
Natural Selection, inc.: David Fogel. Evolution, board games.
University of Essex: Simon Lucas, Julian Togelius. Neuroevolution, board games, Pac-man, car racing.
University of Iceland: Thomas P. Runarsson. Evolution, reinforcement learning, board games.
University of Nevada, Reno: Sushil J. Louis. Evolution, strategy games.
University of Paisley: Benoit Chaperot, Colin Fyfe. Motocross racing.
University of Pretoria: Andries P. Engelbrecht. Particle swarm optimization, board games.
University of Southern Denmark: Henrik Hautop Lund, Georgios N. Yannakakis. Player modeling, Pac-man.
University of Texas, Austin: Bobby Bryant, Risto Miikkulainen. Neuroevolution, strategy games.
The format of the list would be the institution (university, company etc.), followed by a list of relevant researchers (those who spend a significant amount of their time on CIG research), and possibly a few words about what the topics of research are. The list is meant to be continuously updated: I am fully aware it is far from complete at the moment, so please help me expand it by posting additions and corrections to the list in the comments below! This post will then be updated as additions come in.
Brandeis University: Jordan Pollack. Co-evolution, theory, backgammon.
Natural Selection, inc.: David Fogel. Evolution, board games.
University of Essex: Simon Lucas, Julian Togelius. Neuroevolution, board games, Pac-man, car racing.
University of Iceland: Thomas P. Runarsson. Evolution, reinforcement learning, board games.
University of Nevada, Reno: Sushil J. Louis. Evolution, strategy games.
University of Paisley: Benoit Chaperot, Colin Fyfe. Motocross racing.
University of Pretoria: Andries P. Engelbrecht. Particle swarm optimization, board games.
University of Southern Denmark: Henrik Hautop Lund, Georgios N. Yannakakis. Player modeling, Pac-man.
University of Texas, Austin: Bobby Bryant, Risto Miikkulainen. Neuroevolution, strategy games.
AI: All fun and games
Who believes in artificial intelligence (AI) nowadays? Not many, it seems.
For some fifty years, computer scientists have been saying that they know the principles for creating intelligent machines, and that a working piece of AI hardware of software is just around the corner. Or maybe around the next corner. People nowadays seem not so much to take those claims with a pinch of salt as they seem to just ignore it.
AI research is all good, the reasoning goes, but all we are likely to get is better chess players, traffic control systems, brain scanners, search engines, rice cookers, or what have you. Human-made technology that autonomously learns and adapts to truly new situations, acting seemingly goal-directed and generally sensible will never appear, because we just don’t know how intelligence such as our own works. Some say that if we were so simple that we could understand ourselves, we would be so stupid that we couldn’t.
Of course, I don’t agree with this.
If I didn’t believe that we will some day create real artificial intelligence, if what I do all day was just plain engineering, I wouldn’t be doing it. (I would probably do something that involved significantly more glamour, girls and sunshine.) But the critics do have a point: we don’t understand how intelligence works right now. Maybe we will understand one day, maybe we won’t.
And this of course makes building an AI using standard engineering techniques, like how we would build a car, a house or an operating system, all but impossible.
Instead, I (and some others with me) think that we can create AI without knowing how it works. The idea is to let the AI build itself, and the method is trial-and-error, or as it is know in biology: Darwinian evolution.
To put it simply, we start with a “population” of randomly generated candidate AI’s, (most often these are software programs in the form of simple brain simulations, or “neural networks”) and we evaluate how good they are at some task. Because they are all randomly generated, they are usually not very good at the task, but some are a little less bad than others, and we keep those. We then delete the worst of the lot, and replace them with slightly changed (“mutated”) copies of the least bad. And then we do that again, and again, and again…
This is so simple that seems it shouldn’t work. But it does. It works in nature – we are intelligent, aren’t we? – and it works in computer simulation. A small community of researchers have been working along these lines for a decade or so; some representative research can be found in the book Evolutionary robotics by Stefano Nolfi and Dario Floreano.
The astute reader will already have noticed a problem with this: this research has been going on for a decade or so, but where is the AI we were promised? Where is HAL, R2D2, Skynet? Not even the car from Knight Rider seems to be ready for the market anytime soon. Indeed, we have a problem. The evolutionary approach works perfectly well for simple problems, but fail to “scale up” to more complex tasks.
I believe this is because the tasks people try to evolve solutions for are not right. What researchers usually do is to teach a robot to do a specific action, like pick up red balls and avoid blue. Ultimately, very little is gained from this, as there is no obvious way to proceed. Once you have learned to pick up red balls, how is that going to help you to brew a good cup of coffee, or take over the world?
It's like a rat learning to push a lever in a skinner box for some food reward. Once it has learnt to push this lever, there is no way to build on this "knowledge" to learn anything interesting.
The right task needs to be simple to get started with, yet more or less limitless in its ultimate complexity, and with a good learning curve so you can make continuous progress. Like life, or like a well-designed computer game.
Indeed, some games (mostly puzzles and board games) are marketed as taking "a minute to learn, but a lifetime to master". That's exactly what we're looking for. But this doesn't only apply to board games. The basic principles behind a carefully designed FPS like counter-strike are grasped in almost no time at all, but many people play it every day for several years and keep getting better at it!
At the moment we are working with a simple car racing game. Racing games are in a way ideal, as more or less anyone can pick up the controller and race a lap, but to become a racing champion requires a lifetime of practice, and quite a bit of intelligence. For example, you need to be able to plan your path, keep track of your opponents and anticipate their actions. I am making steady progress on having my AI’s teach themselves how to do this - ssee the videos.
But will automatic development of car racing AI really be a stepping stone toward general intelligence? I think so, but you are welcome to disagree with me - I'd love to hear why it wouldn't. And in any case, it will at least make for better racing games.
For some fifty years, computer scientists have been saying that they know the principles for creating intelligent machines, and that a working piece of AI hardware of software is just around the corner. Or maybe around the next corner. People nowadays seem not so much to take those claims with a pinch of salt as they seem to just ignore it.
AI research is all good, the reasoning goes, but all we are likely to get is better chess players, traffic control systems, brain scanners, search engines, rice cookers, or what have you. Human-made technology that autonomously learns and adapts to truly new situations, acting seemingly goal-directed and generally sensible will never appear, because we just don’t know how intelligence such as our own works. Some say that if we were so simple that we could understand ourselves, we would be so stupid that we couldn’t.
Of course, I don’t agree with this.
If I didn’t believe that we will some day create real artificial intelligence, if what I do all day was just plain engineering, I wouldn’t be doing it. (I would probably do something that involved significantly more glamour, girls and sunshine.) But the critics do have a point: we don’t understand how intelligence works right now. Maybe we will understand one day, maybe we won’t.
And this of course makes building an AI using standard engineering techniques, like how we would build a car, a house or an operating system, all but impossible.
Instead, I (and some others with me) think that we can create AI without knowing how it works. The idea is to let the AI build itself, and the method is trial-and-error, or as it is know in biology: Darwinian evolution.
To put it simply, we start with a “population” of randomly generated candidate AI’s, (most often these are software programs in the form of simple brain simulations, or “neural networks”) and we evaluate how good they are at some task. Because they are all randomly generated, they are usually not very good at the task, but some are a little less bad than others, and we keep those. We then delete the worst of the lot, and replace them with slightly changed (“mutated”) copies of the least bad. And then we do that again, and again, and again…
This is so simple that seems it shouldn’t work. But it does. It works in nature – we are intelligent, aren’t we? – and it works in computer simulation. A small community of researchers have been working along these lines for a decade or so; some representative research can be found in the book Evolutionary robotics by Stefano Nolfi and Dario Floreano.
The astute reader will already have noticed a problem with this: this research has been going on for a decade or so, but where is the AI we were promised? Where is HAL, R2D2, Skynet? Not even the car from Knight Rider seems to be ready for the market anytime soon. Indeed, we have a problem. The evolutionary approach works perfectly well for simple problems, but fail to “scale up” to more complex tasks.
I believe this is because the tasks people try to evolve solutions for are not right. What researchers usually do is to teach a robot to do a specific action, like pick up red balls and avoid blue. Ultimately, very little is gained from this, as there is no obvious way to proceed. Once you have learned to pick up red balls, how is that going to help you to brew a good cup of coffee, or take over the world?
It's like a rat learning to push a lever in a skinner box for some food reward. Once it has learnt to push this lever, there is no way to build on this "knowledge" to learn anything interesting.
The right task needs to be simple to get started with, yet more or less limitless in its ultimate complexity, and with a good learning curve so you can make continuous progress. Like life, or like a well-designed computer game.
Indeed, some games (mostly puzzles and board games) are marketed as taking "a minute to learn, but a lifetime to master". That's exactly what we're looking for. But this doesn't only apply to board games. The basic principles behind a carefully designed FPS like counter-strike are grasped in almost no time at all, but many people play it every day for several years and keep getting better at it!
At the moment we are working with a simple car racing game. Racing games are in a way ideal, as more or less anyone can pick up the controller and race a lap, but to become a racing champion requires a lifetime of practice, and quite a bit of intelligence. For example, you need to be able to plan your path, keep track of your opponents and anticipate their actions. I am making steady progress on having my AI’s teach themselves how to do this - ssee the videos.
But will automatic development of car racing AI really be a stepping stone toward general intelligence? I think so, but you are welcome to disagree with me - I'd love to hear why it wouldn't. And in any case, it will at least make for better racing games.
Monday, May 15, 2006
What makes racing fun?
Me and Renzo are working on a paper on how to automatically create fun racing tracks. And not only that, but racing tracks that are fun just for you - which means that we must first model how you drive with a neural network, and then use this model of your driving to create the tracks.
Grand plans, but will it work? Well, we'll see soon. In the meantime, here's a question for all of you: what exactly is it that makes a racing game fun? And what is it that makes a particular track/circuit in racing game fun?
Of course, in the end we want some quantitative measure we can put into our code, but the quantitative part is really up to us. What we're looking for right now is suggestions, ideas. Any sort. What makes racing fun? Please leave your comment below!
Grand plans, but will it work? Well, we'll see soon. In the meantime, here's a question for all of you: what exactly is it that makes a racing game fun? And what is it that makes a particular track/circuit in racing game fun?
Of course, in the end we want some quantitative measure we can put into our code, but the quantitative part is really up to us. What we're looking for right now is suggestions, ideas. Any sort. What makes racing fun? Please leave your comment below!
Wednesday, May 10, 2006
Slashdotted! (Well, sort of...)
I posted a question to Ask Slashdot a few days ago, which recently got up on the front page and has at the time being had 190 replies:
What Would You Like to See from Game AI?
(Incidentally, it seems to have generated quite a bit of traffic to this blog as well...)
So what can I say about the answers? Well, there seems to be a lot of variance in what people want, or think they want. The two most common requests are AI that learns (from the player, or from past behaviour) or just "lives its own life", and AI whose reasoning is understandable/transparent/believable. While I certainly agree with the learning and adaptation bit - that is very much what I am working on - I am not so sure about the other request. Architectures that learn are generally not very good at explaining why they do what they do, but usually very good at coming up with behaviour you didn't expect when you designed them.
Do people really want to understand why agents in games do what they do? And to what extent? Surely it becomes boring when you can predict every move of your opponent, but I suppose a game where the opponents act seemingly randomly is not so fun either. Maybe there's a tradeoff. But then again, isn't there a difference between seemingly random behaviour, and seemingly random but obviously effective and therefore somehow goal-directed behaviour? The sort of difference that makes people go to great lengths to understand the behaviour?
Of particular note is the poster who complained about racing games that adapt their difficulty level to the human player, and thus ends up winning in the last lap however well you drive. But that's not AI. That's just adapting a difficulty setting. A game that not just adapted to your skill, but instead adapted to counter your particular driving style, would be much more interesting. And you would learn more from it.
What Would You Like to See from Game AI?
(Incidentally, it seems to have generated quite a bit of traffic to this blog as well...)
So what can I say about the answers? Well, there seems to be a lot of variance in what people want, or think they want. The two most common requests are AI that learns (from the player, or from past behaviour) or just "lives its own life", and AI whose reasoning is understandable/transparent/believable. While I certainly agree with the learning and adaptation bit - that is very much what I am working on - I am not so sure about the other request. Architectures that learn are generally not very good at explaining why they do what they do, but usually very good at coming up with behaviour you didn't expect when you designed them.
Do people really want to understand why agents in games do what they do? And to what extent? Surely it becomes boring when you can predict every move of your opponent, but I suppose a game where the opponents act seemingly randomly is not so fun either. Maybe there's a tradeoff. But then again, isn't there a difference between seemingly random behaviour, and seemingly random but obviously effective and therefore somehow goal-directed behaviour? The sort of difference that makes people go to great lengths to understand the behaviour?
Of particular note is the poster who complained about racing games that adapt their difficulty level to the human player, and thus ends up winning in the last lap however well you drive. But that's not AI. That's just adapting a difficulty setting. A game that not just adapted to your skill, but instead adapted to counter your particular driving style, would be much more interesting. And you would learn more from it.
Thursday, April 27, 2006
Evolutionary car racing videos
I've put up a few videos of our evolved car racing controllers. The fascinating thing is that no human has told the cars you will see below how to drive, or indeed how to maneuver aggressively so that competitors crash into walls. Instead, me and Simon used evolution strategies (similar to genetic algorithms) to evolve neural networks (sort of simple simulated brains) that control the cars. It's plain simple survival of the fittest - we start with random networks, and see who can drive the car furthest in a set time. To start with, all of the networks are pretty bad, but some are less bad than the others, so we allow them to "reproduce" (being copied) with small changes, and repeat the process... Just like in nature, this seemingly random process produces seemingly intelligent behaviour.
To start with, this is a single car driving one of the standard tracks:
The inputs to the neural networks are sort of simulated rangefinder sensors (e.g. ir or sonar) as shown below, the network is a three-layer MLP (probably the most common type of neural network), and the outputs are motor and steering commands:

The paper detailing the original experiments, where we compared neural networks and rangefinder sensors with other architectures, is here. A follow-up paper, where we evolved cars to be able to drive several different tracks, is here. This was done by evolving the network to drive the car on one track, and then step by step letting the network teach itself new tracks. There are many tricks to making this work properly, such as starting with fixed sensor positions but later letting the evolutionary process handle the positioning of the sensors.
Most recently, we submitted a paper (not available online yet) to the conference PPSN about co-evolving several cars to drive against each other. Have a look at the following:
We did notice a few interesting things concerning the interaction of the cars in the course of the experiments. One was that what went into the fitness function - in other words, what we rewarded the neural networks for doing - had a drastic effect on the cars' behaviour. If we used a fitness function where the neural network was rewarded for its car being in front of the other car, regardless of how far along the track it was, we often saw some pretty aggressive driving with cars actively crashing into each other and trying to force each other off the track. If, on the other hand, we rewarded the networks just for getting far along the tracks, the cars usually avoided collisions. Check out the following examples of vicious neural network-drivers:
The last example shows that we still have some way to go: sometimes the outcome of the race is that both cars find themselves stuck against some wall. So far, the cars haven't found out how to back away from a wall and resume the correct course. We're working on more complex neural networks and sensors to overcome this.
Of course, I hope that these technologies will some day be incorporated into actual racing games (which shouldn't be impossible, looking at the sorry state of most game AI) and physical vehicles. But along the way, I think there is a lot to be learned about how the evolution and learning of behaviour works, and I think that games are the ideal environment for doing that research in. More on that in a later post.
To start with, this is a single car driving one of the standard tracks:
The inputs to the neural networks are sort of simulated rangefinder sensors (e.g. ir or sonar) as shown below, the network is a three-layer MLP (probably the most common type of neural network), and the outputs are motor and steering commands:
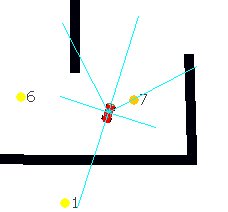
The paper detailing the original experiments, where we compared neural networks and rangefinder sensors with other architectures, is here. A follow-up paper, where we evolved cars to be able to drive several different tracks, is here. This was done by evolving the network to drive the car on one track, and then step by step letting the network teach itself new tracks. There are many tricks to making this work properly, such as starting with fixed sensor positions but later letting the evolutionary process handle the positioning of the sensors.
Most recently, we submitted a paper (not available online yet) to the conference PPSN about co-evolving several cars to drive against each other. Have a look at the following:
We did notice a few interesting things concerning the interaction of the cars in the course of the experiments. One was that what went into the fitness function - in other words, what we rewarded the neural networks for doing - had a drastic effect on the cars' behaviour. If we used a fitness function where the neural network was rewarded for its car being in front of the other car, regardless of how far along the track it was, we often saw some pretty aggressive driving with cars actively crashing into each other and trying to force each other off the track. If, on the other hand, we rewarded the networks just for getting far along the tracks, the cars usually avoided collisions. Check out the following examples of vicious neural network-drivers:
The last example shows that we still have some way to go: sometimes the outcome of the race is that both cars find themselves stuck against some wall. So far, the cars haven't found out how to back away from a wall and resume the correct course. We're working on more complex neural networks and sensors to overcome this.
Of course, I hope that these technologies will some day be incorporated into actual racing games (which shouldn't be impossible, looking at the sorry state of most game AI) and physical vehicles. But along the way, I think there is a lot to be learned about how the evolution and learning of behaviour works, and I think that games are the ideal environment for doing that research in. More on that in a later post.
Saturday, April 22, 2006
This is me
Last summer, I volunteered to be a subject in some BCI (Brain-Computer Interface) research. Hinrik, an MSc student I also used to go out and get drunk with (and try to avoid fighting with squaddies, but that's another story) was doing a project on robot control via EEG. He fitted lots of electrodes on my head, and I had to think of moving (without moving) while watching a robot move. This is what I looked like:

Nice, eh?
BCI is definitely an interesting field, and the BCI group here at Essex seems to contest of thoroughly nice (and competent!) people. I wouldn't mind being more involved in such research...
...but no, I have enough to do as it is. And I'm quite happy with what I do.

Nice, eh?
BCI is definitely an interesting field, and the BCI group here at Essex seems to contest of thoroughly nice (and competent!) people. I wouldn't mind being more involved in such research...
...but no, I have enough to do as it is. And I'm quite happy with what I do.
Evolutionary sudoku solving
Alberto, me, and Simon recently got our paper on evolutionary sudoku solving accepted at CEC 2006. We thought we were the first researchers in the world to apply evolutionary algorithms to Sudoku, but according to one of the reviewers, we actually came second, as another paper on EC and Sudoku was accepted to Euro-GP a month or so earlier.
Anyway, our experiments worked really well. A quick introduction, for those who don't think in terms of evolutionary algorithms: We start with the empty sudoku grid, empty except for the fixed positions that define the puzzle. The algorithm, in its very simplest version, then fills in the empty positions with random numbers between one and nine. At each generation, a random change (mutation) was made to each grid, by changing one of the non-fixed numbers to another random number between one and nine. At the end of each generation, the fitness of each grid was evaluated by counting the number of unique elements in each row, grid and square. The grids with highest fitness were kept for next generation, and those with lower fitness were replaced with mutated clones of those with higher fitness, just like in nature. After a number of generations, such an algorithm actually solves most, if not all, Sudoku problems!
Not that our evolutionary algorithms solved sudoku grids faster than existing methods that take into account the structure of the problem - it is doubtful whether evolution will ever do that, at least for standard-size grids. But our main aim was to verify some predictions from Alberto's theory using Sudoku as a testbed.
Alberto's theory is about geometric crossover. In my description I omitted crossover - when a new individuals (in this case a new Sudoku grid) is created by mixing two parents (in this case two other Sudoku grids). Actually, many evolutionary algorithms don't use crossover, because it is so tricky to get it right - it can easily end up doing more harm than good. But when it's used right it can actually improve the efficiency of an evolutionary algorithm dramatically. The highly mathematical theory of Alberto is about exactly what sort of crossover is appropriate for what problem representation. Greatly simplified, it says that the offspring should be somewhere between its parents in the multidimensional space of representations. And it turned out that the crossover operators designed according to this theory indeed were very effective.
But enough about this - go read the paper to get to know more! The source code is available if you want to do your own experiments.
Anyway, our experiments worked really well. A quick introduction, for those who don't think in terms of evolutionary algorithms: We start with the empty sudoku grid, empty except for the fixed positions that define the puzzle. The algorithm, in its very simplest version, then fills in the empty positions with random numbers between one and nine. At each generation, a random change (mutation) was made to each grid, by changing one of the non-fixed numbers to another random number between one and nine. At the end of each generation, the fitness of each grid was evaluated by counting the number of unique elements in each row, grid and square. The grids with highest fitness were kept for next generation, and those with lower fitness were replaced with mutated clones of those with higher fitness, just like in nature. After a number of generations, such an algorithm actually solves most, if not all, Sudoku problems!
Not that our evolutionary algorithms solved sudoku grids faster than existing methods that take into account the structure of the problem - it is doubtful whether evolution will ever do that, at least for standard-size grids. But our main aim was to verify some predictions from Alberto's theory using Sudoku as a testbed.
Alberto's theory is about geometric crossover. In my description I omitted crossover - when a new individuals (in this case a new Sudoku grid) is created by mixing two parents (in this case two other Sudoku grids). Actually, many evolutionary algorithms don't use crossover, because it is so tricky to get it right - it can easily end up doing more harm than good. But when it's used right it can actually improve the efficiency of an evolutionary algorithm dramatically. The highly mathematical theory of Alberto is about exactly what sort of crossover is appropriate for what problem representation. Greatly simplified, it says that the offspring should be somewhere between its parents in the multidimensional space of representations. And it turned out that the crossover operators designed according to this theory indeed were very effective.
But enough about this - go read the paper to get to know more! The source code is available if you want to do your own experiments.
Subscribe to:
Posts (Atom)



