The most important thing for humanity to do right now is to invent true artificial intelligence (AI): machines or software that can think and act independently in a wide variety of situations. Once we have artificial intelligence, it can help us solve all manner of other problems.
Luckily, thousands of researchers around work on inventing artificial intelligence. While most of them work on ways of using known AI algorithms to solve new problems, some work on the overarching problem of artificial general intelligence. I do both. As I see it, addressing applied problems spur the invention of new algorithms, and the availability of new algorithms make it possible to address new problems. Having concrete problems to try to solve with AI is necessary in order to make progress; if you try to invent AI without having something to use it for, you will not know where to start. My chosen domain is games, and I will explain why this is the most relevant domain to work on if you are serious about AI.
 |
| I talk about this a lot. All the time, some would say. |
But first, let us acknowledge that AI has gotten a lot of attention recently, in particular work on "deep learning" is being discussed in mainstream press as well as turned into startups that get bought by giant companies for bizarre amounts of money. There have been some very impressive advances during the past few years in identifying objects in images, understanding speech, matching names to faces, translating text and other such tasks. By some measures, the winner of the
recent ImageNet contest is better than humans at correctly naming things in images; sometimes I think Facebook's algorithms are better than me at recognizing the faces of my acquaintances.
 |
| Example image from the ImageNet competition. "Deep" neural networks have been made to learn to label images extremely well lately. Image courtesy of image-net.org. |
With few exceptions, the tasks that deep neural networks have excelled at are what are called pattern recognition problems. Basically, take some large amount of data (an image, a song, a text) and output some other (typically smaller) data, such as a name, a category, another image or a text in another language. To learn to do this, they look at tons of data to find patterns. In other words, the neural networks are learning to do the same work as our brain's sensory systems: sight, hearing, touch and so on. To a lesser extent they can also do some of the job of our brain's language centra.
However, this is not all that intelligence is. We humans don't just sit around and watch things all day. We do things: solve problems by taking decisions and carrying them out. We move about and we manipulate our surroundings. (Sure, some days we stay in bed almost all day, but most of the rest of the time we are active in one way or another.) Our intelligence evolved to help us survive in a hostile environment, and doing that meant both reacting to the world and planning complicated sequences of actions, as well as adapting to changing circumstances. Pattern recognition - identifying objects and faces, understanding speech and so on - is an important component of intelligence, but should really be thought of as one part of a complete system which is constantly working on figuring out what to do next. Trying to invent artificial intelligence while only focusing on pattern recognition is like trying to invent the car while only focusing on the wheels.
In order to build a complete artificial intelligence we therefore need to build a system that takes actions in some kind of environment. How can we do this? Perhaps the most obvious idea is to embody artificial intelligence in robots. And indeed, robotics has shown us how even the most mundane tasks, such as walking in terrain or grabbing strangely shaped objects, are really rather hard to accomplish for robots. In the eighties, robotics research largely refocused on these kind of "simple" problems, which led to progress in applications as well as a better understanding of what intelligence is all about. The last few decades of progress in robotics has fed into the development of self-driving cars, which is likely to become one of the areas where AI technology will revolutionize society in the near future.
 |
| Once upon a time, when I thought I was a roboticist of sorts. The carlike robot in the foreground was supposed to learn to independently drive around the University of Essex campus (in the background). I think it's fair to say we underestimated the problem. (From left to right: me (now at NYU), Renzo de Nardi (Google), Simon Lucas (Essex), Richard Newcombe (Facebook/Oculus), Hugo Marques (ETH Zurich).) |
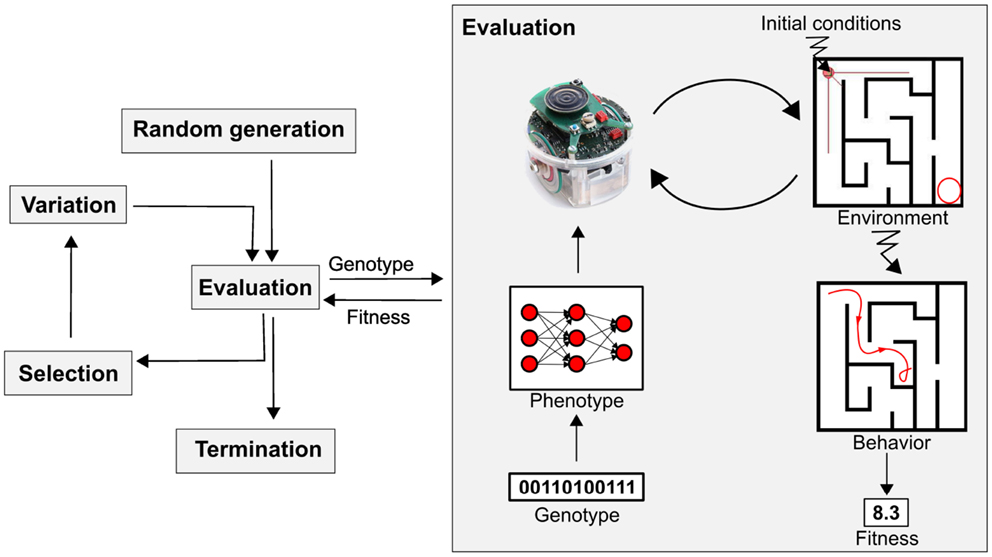
Now, working with robots clearly has its downsides. Robots are expensive, complex and slow. When I started my PhD, my plan was to build robot software that would learn evolutionarily from its mistakes in order to develop increasingly complex and general intelligence. But I soon realized that in order for my robots to learn from their experiences, they would have to attempt each task thousands of times, with each attempt maybe taking a few minutes. This meant that even a simple experiment would take several days - even if the robot would not break down (it usually would) or start behaving differently as the batteries depleted or motors warmed up. In order to learn any more complex intelligence I would have to build an excessively complex (and expensive) robot with advanced sensors and actuators, further increasing the risk of breakdown. I also would have to develop some very complex environments where complex skills could be learned. This all adds up, and quickly becomes unmanageable. Problems such as these is why the field of evolutionary robotics has not scaled up to evolve more complex intelligence.
 |
| The basic idea of evolutionary robotics: use Darwinian evolution implemented as a computer algorithm to teach robot AIs (for example neural networks) to solve tasks. Image taken from a recent survey paper. |
I was too ambitious and impatient for that. I wanted to create complex intelligence that could learn from experience. So I turned to video games.
Games and artificial intelligence have a long history together. Even since before artificial intelligence was recognized as a field, early pioneers of computer science wrote game-playing programs because they wanted to test whether computers could solve tasks that seemed to require "intelligence". Alan Turing, arguably the principal inventor of computer science,
(re)invented the Minimax algorithm and used it to play Chess. (As no computer had been built yet, he performed the calculations himself using pen and paper.) Arthur Samuel was the first to invent the form of machine learning that is now called reinforcement learning; he used it in
a program that learned to play Checkers by playing against itself. Much later,
IBM's Deep Blue computer famously won against the reigning grandmaster of Chess, Gary Kasparov, in a much-publicized 1997 event. Currently, many researchers around the world work on developing better software for playing the board game Go, where
the best software is still no match for the best humans.
 |
| Arthur Samuel in 1957, playing checkers against a mainframe computer the size of a room and thousands of times less computer power than your phone. The computer won. |
Classic board game such as Chess, Checkers and Go are nice and easy to work with as they are very simple to model in code and can be simulated extremely fast - you could easily make millions of moves per second on a modern computer - which is indispensable for many AI techniques. Also, they seem to require thinking to play well, and have the property that they take "a minute to learn, but a lifetime to master". It is indeed the case that games have a lot to do with learning, and good games are able to constantly teach us more about how to play them. Indeed, to some extent
the fun in playing a game consists in learning it and when there is nothing more to learn we largely stop enjoying them. This suggests that better-designed games are also better benchmarks for artificial intelligence. However, judging from the fact that now have (relatively simple) computer programs that can play Chess better than any human, it is clear that you don't need to be truly, generally intelligent to play such games well. When you think about it, they exercise only a very narrow range of human thinking skills; it's all about turn-based movements on a discrete grid of a few pieces with very well-defined, deterministic behavior.
 |
| Deep Blue beats Kasparov in Chess. |
But, despite what your grandfather might want you to believe, there's more to games than classical board games. In addition to all kinds of modern boundary-pushing board games, card games and role-playing games, there's also video games. Video games owe their massive popularity at least partly to that they engage multiple senses and multiple cognitive skills. Take a game such as Super Mario Bros. It requires you not only to have quick reactions, visual understanding and motoric coordination, but also to plan a path through the level, decide about tradeoffs between various path options (which include different risks and rewards), predict the future position and state of enemies and other characters of the level, predict the physics of your own running and jumping, and balance the demands of limited time to finish the level with multiple goals. Other games introduce demands of handling incomplete information (e.g. StarCraft), understanding narrative (e.g. Skyrim), or very long-term planning (e.g. Civilization).
 |
| A very simple car racing game I hacked up for a bunch of experiments that went into my PhD thesis. We also used it for a competition. |
On top of this, video games are run inside controllable environments in a computer and many (though not all) video games can be sped up to many times the original speed. It is simple and cheap to get started, and experiments can be run many thousand times in quick succession, allowing the use of learning algorithms.
So it is not surprising that AI researchers have increasingly turned to video games as benchmarks recently. Researchers such as myself have adapted a number of video games to function as AI benchmarks. In many cases we have organized competitions where researchers can submit their best game-playing AIs and test them against the best that other researchers can produce; having recurring competitions based on the same game allows competitors to refine their approaches and methods, hoping to win next year. Games for which we have run such competitions include Super Mario Bros (
paper), StarCraft (
paper), the TORCS racing game (
paper), Ms Pac-Man (
paper), a generic Street Fighter-style figthing game (
paper), Angry Birds (
paper), Unreal Tournament (
paper) and several others. In most of these competitions, we have seen performance of the winning AI player improve every time the competition is run. These competitions play an important role in catalyzing research in the community, and every year many papers are published where the competition software is used for benchmarking some new AI method. Thus, we advance AI through game-based competitions.
There's a problem with the picture I just painted. Can you spot it?
That's right. Game specificity. The problem is that improving how well an artificial intelligence plays a particular game is not necessarily helping us improve artificial intelligence in general. It's true that in most of the game-based competitions mentioned above we have seen the submitted AIs get better every time the competition ran. But in most cases, the improvements were not because of better AI algorithms, but because of even more ingenious ways of using these algorithms for the particular problems. Sometimes this meant relegating the AI to a more peripheral role. For example, in the car racing competition the first years were dominated by AIs that used evolutionary algorithms to train a neural network to keep the car on the track. In later years, most of the best submissions used hand-crafted "dumb" methods to keep the car on the track, but
used learning algorithms to learn the shape of the track to adapt the driving. This is a clever solution to a very specific engineering problem but says very little about intelligence in general.
 |
| The game Ms. Pac-Man was used in a successful recent AI competition, which saw academic researchers, students and enthusiasts from around the world submit their AI Pac-Man players. The challenge of playing Pac-Man spurred researchers to invent new versions of state-of-the-art algorithms to try to get ahead. Unfortunately, the best computer players so far are no better than an intermediate human. |
In order to make sure that what such a competition measures is anything approaching actual intelligence, we need to recast the problem. To do this, it's a great idea to define what it is we want to measure: general intelligence. Shane Legg and Marcus Hutter have proposed
a very useful definition of intelligence, which is roughly the average performance of an agent on all possible problems. (In their original formulation, each problem's contribution to the average is weighed by its simplicity, but let's disregard that for now.) Obviously, testing an AI on all possible problems is not an option, as there are infinitely many problems. But maybe we could test our AI on just a sizable number of diverse problems? For example
on a number of different video games?
The first thing that comes to mind here is to just to take a bunch of existing games for some game console, preferably one that could be easily emulated and sped up to many times real time speed, and build an AI benchmark on them. This is what the
Arcade Learning Environment (ALE) does. ALE lets you test your AI on more than a hundred games released for 70s vintage Atari 2600 console. The AI agents get feeds of the screen at pixel level, and have to respond with a joystick command. ALE has been used in a number of experiments, including those by the original developers of the framework. Perhaps most famously,
Google Deep Mind published a paper in Nature showing how they could learn to play several of the games with superhuman skill using deep learning (Q-learning on a deep convolutional network).
 |
| The Atari 2600 video game console. Note the 1977-vintage graphics of the Combat game on the TV in the background. Note, also, the 1977-vintage wooden panel. Your current game console probably suffers from a lack of wooden panels. Not in picture: 128 bytes of memory. That's a few million times less than your cell phone. |
ALE is an excellent AI benchmark, but has a key limitation. The problem with using Atari 2600 games is that there is only a finite number of them, and developing new games is a trick process. The Atari 2600 is notoriously hard to program, and the hardware limitations of the console tightly constrain what sort of games can be implemented. More importantly, all of the existing games are known and available to everyone. This makes it possible to tune your AI to each particular game. Not only to train your AI for each game (DeepMind's results depend on playing each game many thousands of times to train on it) but to tune your whole system to work better on the games you know you will train on.
Can we do better than this? Yes we can! If we want to approximate testing our AI on all possible problems, the best we can do is to test it on a number of unseen problems. That is, the designer of the AI should not know which problems it is being tested on before the test. At least, this was our reasoning when we designed the General Video Game Playing Competition.
 |
| "Frogger" for the Atari 2600. |
The
General Video Game Playing Competition (GVGAI) allows anyone to submit their best AI players to a special server, which will then use them to play ten games that no-one (except the competition organizers) have seen before. These games are of the type that you could find on home computers or in arcades in the early eighties; some of them are based on existing games such as Boulder Dash, Pac-Man, Space Invaders, Sokoban and Missile Command. The winner of the competition is the AI that plays these unseen games best. Therefore, it is impossible for the creator of the AI to tune their software to any particular game. Around 50 games are available for training your AI on, and every iteration of the competition increases this number as the testing games from the previous iteration become available to train on.
 |
| "Frogger" implemented in VGDL in the General Video Game Playing framework. |
Now, 50 games is not such a large number; where do we get new games from? To start with, all the games are programmed in something called the
Video Game Description Language (VGDL). This is a simple language we designed to to be able to write games in a compact and human-readable way, a bit like how HTML is used to write web pages.
The language is designed explicitly to be able to encode classical arcade games; this means that the games are all based on the movement of and interaction sprites in two dimensions. But that goes for essentially all video games before Wolfenstein 3D. In any case, the simplicity of this language makes it very easy to write new games, either from scratch or as variations on existing games. (Incidentally, as an offshoot of this project we are exploring the use of VGDL as a prototyping tool for game developers.)
 |
| A simple version of the classic puzzle game Sokoban implemented in VGDL. |
Even if it's simple to write new games, that doesn't solve the fundamental problem that someone has to write them, and design them first. For the GVG-AI competition to reach its full potential as a test of general AI, we need an endless supply of new games. For this, we need to generate them. We need software that can produce new games at the press of a button, and these need to be good games that are not only playable but also require genuine skill to win. (As a side effect, such games are likely to be enjoyable for humans.)
 |
| Boulder Dash implemented in VGDL in the General Video Game Playing framework. |
I know, designing software that can design complete new games (that are also good in some sense) sounds quite hard. And it is. However, I and a couple of others have been working on this problem on and off for a couple of years, and I'm firmly convinced it is doable. Cameron Browne has already managed to
build a complete generator for playable (and enjoyable) board games, and some of our recent work has focused on
generating simple VGDL games, though there is much left to do. Also, it is clearly possible to generate parts of games, such as game levels; there has been plenty of research within the last five years on
procedural content generation - the automatic generation of game content. Researchers have demonstrated that methods such as
evolutionary algorithms, planning and
answer set programming can automatically create levels, maps, stories, items and geometry, and basically any other content type for games. Now, the research challenges are to make these methods general (so that they work for all games, not just for a particular game) and more comprehensive, so that they can generate all aspects of a game including the rules. Most of the generative methods include some form of simulation of the games that are being generated, suggesting that the problems of game playing and game generation are intricately connected and should be considered together whenever possible.
 |
| Yavalath, a board game designed by computer program designed by Cameron Browne. Proof that computers can design complete games. |
Once we have extended the General Video Game Playing Competition with automated game generation, we have a much better way of testing generic game-playing ability than we have ever had before. The software can of course also be used outside of the competition, providing a way to easily test the general intelligence of game-playing AI.
So far we have only talked about how to best test or evaluate the general intelligence of a computer program, not how to best create one. Well, this post is about why video games are essential for inventing AI, and I think that I have explained that pretty well: they can be used to fairly and accurately benchmark AIs. But for completeness, let us consider which are the most promising methods for creating AIs of this kind. As mentioned above, (deep) neural networks have recently attracted lots of attention because of some spectacular results in pattern recognition. I believe neural networks and similar pattern recognition methods will have an important role to play for evaluating game states and suggesting actions in various game states. In many cases,
evolutionary algorithms are more suitable than gradient-based methods when training neural networks for games.
But intelligence can not only be pattern recognition. (This is for the same reason that behaviorism is not a complete account of human behavior: people don't just map stimuli to responses§, sometimes they also think.) Intelligence must also incorporate some aspect of planning, where future sequences of actions can be played out in simulation before deciding what to do. Recently an algorithm called
Monte Carlo Tree Search, which simulates the consequences of long sequences of actions by doing statistics of random actions, has worked wonders on the board game Go. It has also done very well on GVGAI. Another family of algorithms that has recently shown great promise on game planning tasks is
rolling horizon evolution. Here, evolutionary algorithms are used not for long-term learning, but for short-term action planning.
I think the next wave of advances in general video game-playing AIs will come from ingenious combinations of neural networks, evolution and tree search. And from algorithms inspired by these methods. The important thing is that both pattern recognition and planning will be necessary in various different capacities. As usual in research, we cannot predict what will work well in the future (otherwise it wouldn't be called research), but I bet that exploring various combinations of these method will inspire the invention of the next generation of AI algorithms.
 |
| A video game such as The Elder Scrolls V: Skyrim requires a wide variety of cognitive skills to play well. |
Now, you might object that this is a very limited view of intelligence and AI. What about text recognition, listening comprehension, storytelling, bodily coordination, irony and romance? Our game-playing AIs can't do any of this, no matter if it can play all the arcade games in the world perfectly. To this I say: patience! None of these things are required for playing early arcade games, that is true. But as we master these games and move on to include other genres of games in our benchmark, such as role-playing games, adventure games, simulation games and social network games, many of these skills will be required to play well. As we gradually increase the diversity of games we include in our benchmark, we will also gradually increase the breadth of cognitive skills necessary to play well. Of course, our game-playing AIs will have to get more advanced to cope. Understanding language, images, stories, facial expression and humor will be necessary. And don't forget that closely coupled with the challenge of general video game playing is the challenge of general video game generation, where plenty of other types of intelligence will be necessary. I am convinced that video games (in general) challenges all forms of intelligence except perhaps those closely related to bodily movement, and therefore that video game (in general) is the best testbed for artificial intelligence. An AI that can play almost any video game and create a wide variety of video games is, by any reasonable standard, intelligent.
"But why, then, are not most AI researchers working on general video game playing and generation?"
To this I say: patience!
 |
| A game such as Civilization V requires a different, but just as wide, skillset to play well. |
This blog post became pretty long - I had really intended it to be just a fraction of what it is. But there was so much to explain. In case you've read this far, you might very well have forgotten what I said in the beginning by now. So let me recapitulate:
It is crucial for artificial intelligence research to have good testbeds. Games are excellent AI testbeds because they pose a wide variety of challenges, similarly to robotics, and are highly engaging. But they are also simpler, cheaper and faster, permitting a lot of research that is not practically possible with robotics. Board games have been used in AI research since the field started, but in the last decade more and more researchers have moved to video games because they offer more diverse and relevant challenges. (They are also more fun.) Competitions play a big role in this. But putting too much effort into AI for a single game has limited value for AI in general. Therefore we created the General Video Game Playing Competition and its associated software framework. This is meant to be the most complete game-based benchmark for general intelligence. AIs are evaluated on playing not a single video game, but on multiple games which the AI designer has not seen before. It is likely that the next breakthroughs in general video game playing will come from a combination of neural networks, evolutionary algorithms and Monte Carlo tree search. Coupled with the challenge of playing these games, is the challenge of generating new games and new content for these games. The plan is to have an infinite supply of games to test AIs on. While playing and generating simple arcade games tests a large variety of cognitive capacities - more diverse than any other AI benchmark - we are not yet at the stage where we test all of intelligence. But there is no reason to think we would not get there, given the wide variety of intelligence that is needed to play and design modern video games.
If you want to know more about these topics, I've linked various blog posts, articles and books from the text above. Most of the research I'm doing (and that we do in the NYU Game Innovation Lab) is in some way connected to the overall project I've been describing here. I recently put together
a little overview of research I've done in the past few years, with links to most of my recent papers. Many more papers can be found on
my web page. It is also important to realize that most of this work has a dual purpose: to advance artificial intelligence and to make games more fun. Many of the technologies that we are developing are to a lesser or greater extent focused on improving games. It's important to note that there is still important work to be done in advancing AI for particular games. In another recent blog post,
I tried to envision what video games would be like if we had actual artificial intelligence. A somewhat recent paper I co-wrote tries to
outline the whole field of AI in games, but it's rather long and complex so I would advise you to read the blog post first. You can also peruse the proceedings of the
Computational Intelligence and Games and
Artificial Intelligence and Interactive Digital Entertainment conference series.
Finally, it's important to note that there is plenty of room to get involved in this line of research (I think of it all as an overarching meta-project) as there are many, many open research questions. So if you are not already doing research on this I think you should start working in this field. It's exciting, because it's the future. So what are you waiting for?