To start with, this is a single car driving one of the standard tracks:
The inputs to the neural networks are sort of simulated rangefinder sensors (e.g. ir or sonar) as shown below, the network is a three-layer MLP (probably the most common type of neural network), and the outputs are motor and steering commands:
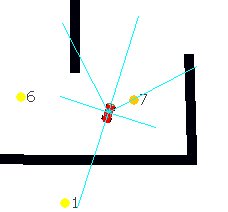
The paper detailing the original experiments, where we compared neural networks and rangefinder sensors with other architectures, is here. A follow-up paper, where we evolved cars to be able to drive several different tracks, is here. This was done by evolving the network to drive the car on one track, and then step by step letting the network teach itself new tracks. There are many tricks to making this work properly, such as starting with fixed sensor positions but later letting the evolutionary process handle the positioning of the sensors.
Most recently, we submitted a paper (not available online yet) to the conference PPSN about co-evolving several cars to drive against each other. Have a look at the following:
We did notice a few interesting things concerning the interaction of the cars in the course of the experiments. One was that what went into the fitness function - in other words, what we rewarded the neural networks for doing - had a drastic effect on the cars' behaviour. If we used a fitness function where the neural network was rewarded for its car being in front of the other car, regardless of how far along the track it was, we often saw some pretty aggressive driving with cars actively crashing into each other and trying to force each other off the track. If, on the other hand, we rewarded the networks just for getting far along the tracks, the cars usually avoided collisions. Check out the following examples of vicious neural network-drivers:
The last example shows that we still have some way to go: sometimes the outcome of the race is that both cars find themselves stuck against some wall. So far, the cars haven't found out how to back away from a wall and resume the correct course. We're working on more complex neural networks and sensors to overcome this.
Of course, I hope that these technologies will some day be incorporated into actual racing games (which shouldn't be impossible, looking at the sorry state of most game AI) and physical vehicles. But along the way, I think there is a lot to be learned about how the evolution and learning of behaviour works, and I think that games are the ideal environment for doing that research in. More on that in a later post.




19 comments:
Hi,
This sounds similar to SANE, from "Forming Neural Networks through Efficient and Adaptive Coevolution" by David E. Moriarty and Risto Miikkulainen.
Did you use SANE, or some novel approach? Is there a paper?
Yes, I am aware of SANE, and I'm quite familiar with (and interested in) NEAT, by another of Risto Miikkulainen's students, Kenneth Stanley. He has published a paper on using that approach to control a car on simulation, which I have also cited in my papers on this (which are here and here).
So far, I've only used simple feedforward MLPs as networks, but I do plan to use some "constructive" neural network approaches. I am especially interested in evolving modular neural networks - I have some papers dealing with the benefits of hard-wired modularity on my homepage, and I'd really like to make some progress on evolving the modular structure as well as the weights of such networks.
Zachrahan, it is interesting that you mention reinforcement learning as I am right this very moment working on learning driving behaviour (using the same simulation) with reinforcement learning. It is not going very well.
I do think that "directed" RL (evolution is strictly speaking also RL, but with undirected changes and a longer timescale) could potentially allow for much faster learning, as much more of the available information is used when local reinforcements are taken into account. But I also think that we need to provide more (or at least different from what I am providing right now) human domain knowledge to make it work properly.
I've seen papers (e.g. one by Jacky Baltes and Yuming Lin) where orthodox/directed RL is used to learn driving behaviour, but they supply completely different information to the controller, such as a precalculated optimal path. That, in my eyes, makes the problem uninteresting. I only give the controller local sensor inputs, which is more interesting to me from several points of view (I prefer to think of what I do in terms of AI or ALife rather than control...). With such inputs, it is not really clear how RL should be applied. Should I learn a policy directly, or a value function? I can't see how direct policy learning would work with RL, and learning the values of locations on the track would be pretty useless if I didn't also have a good model. At the moment I'm trying to learn the values of state/action-pairs, but it is not working very well.
I am aware of Ng's work on RL for helicopter control - we have a forthcoming CEC paper that shows that this can be done nicely with evolution as well.
Nice stuff. I've done some similar work involving cars tracking a moving target in an open environment. I use pulsing neurons that can be implemented as circuits, and better yet, you only need four neurons to do a pretty good job. I used asexual reproduction with defects to optimise the network parameters quite successfully. You can play around with everything an simulate using Java Web Start - check it out:
http://www.polymtl.ca/lrn/dungen/PulsingSOM/
http://www.polymtl.ca/lrn/dungen/PulsingSOM/ApplicationOne/JApplicationOne.jnlp
http://www.polymtl.ca/lrn/dungen/PulsingSOM/ApplicationOne/JApplicationTwo.jnlp
Jeff Dungen
:)
try progression feedback.
Hallo!!
Very nice post, friend!
I put a post at my blog (Genetic Argonaut)
Here you are a direct link to the post about your Evolved Racing Cars:
Evolving Racing Cars Through Evolution Strategy.
I added your blog to the links of mine. :D
See You!
Marcelo
Hallo!
As you applied an Evolution Strategy to evolve your racing cars, I have at my blog a post about the History Of Evolutionary Computation which I call "Evolutionary Computation Classics - Volume I". That post tells us the History of Evolution Strategies and its first steps in Germany, where Ingo Rechenberg, Hans-Paul Schwefel and Peter Bienert made the seminal experiments and simulations.
Até Mais!!
Marcelo
Very nice videos! A posted an entry on by blog about them. See it here
damien
Have you looked into using hierarchical temporal models (HTMs) to create a better understanding of the cars environment? Giving the HTM a stereo video of the forward view of the race track would allow for it to create an invariant representation of the track. The driving decisions could then be extrapolated from the understanding of what the car was looking at, say from a secondary or tertiary component of the invariant representation of "track." Combining this with your evolved system of strategies could boost the effectiveness of the simulations.
-Ian
www.numenta.com - HTMs
Hi, ever thought about experimenting using a good racing simulator such as Torcs? There's robot-driver competitions for it held here as well - might be interesting to pit your ideas against a range of developers using other techniques :)
Hi,
Does anyone know of a good open-source flight simulator with a robot-friendly API?
I was given the URL to your blog from one of the members of our robot club. We'd recently been discussing the use of neural networks in some of our applications, so this caught his eye.
I'm particularly impressed with your choice of sensory input to the network. In a real-world application, range-finders are one of the easier sensors to implement. For short range, IR triangulation sensors like the Sharp GP2D series work well and have fairly narrow beams. For longer range ultrasonic sensors like the ones produced by Devantech would work well, but have much wider beam profiles. I'm curious how a wider beam profile would affect things.
I haven't read the papers you provided links to, but I'll be doing that later today. In the meanwhile, forgive me if you cover these questions in your papers:
Do you mind my asking how many neurons are in your networks? Also, do you have any plans to implement this in a real-world environment? The reason I'm asking is that I've got most of the hardware in my shop to build one of these vehicles with the number of sensors your diagrams indicate. The big question is processing power. I don't have a good feel for how much the processors I'm using can handle, but I was already planning on testing that in the very near future.
A related question: How many iterations did it take before you could evolve a network that could stay on a track reasonably well? This is one of those things that can make a physical hardware model impractical. If it takes thousands of iterations, human patience and endurance, and battery lifetime may be strained a fair bit before something workable comes out of it.
We're very very interested in what you're doing.
Thanks,
Tom
I wonder, if we can apply evolutionary car racing in real life. If to do some improvements, it surely can be used and be helpful.
I think in nearest future Evolved Racing Cars won't be surprise or news for anyone.
http://realtimecollisiondetection.net/blog/?p=36
hi!
this is just great:D I have nothing or very little to do with things like this, so I'm a total amateur to the subject.
benedict
I dont know if it were even more expensive but maybe it would be a solution to "preTrain" your robot.
There are many open source 3d game engines out there, so if you could simulate the sensors you use in real life and build your robot's working 3D model, you could get something very similar to a real experience... This way the robot can learn on its own and when it reaches a level of confidence, you could try it out in a real environment
I do think that "directed" RL (evolution is strictly speaking also RL, but with undirected changes and a longer timescale) could potentially allow for much faster learning, as much more of the available information is used when local reinforcements are taken into account.trachea surgery But I also think that we need to provide more (or at least different from what I am providing right now) human domain knowledge to make it work properly.
Videos are missing. I remember reading this a long time ago and was very impressed. Would be awesome to share this, but find it's not the same without the videos.
Any chance you'll update them to bring them back?
Post a Comment